


Some informal testing of large language models on legal questions
A quick, qualitative snapshot
Like many people, when a new large language model comes out I often give it a whirl by running some questions by it and seeing how it does. I was recently offline for an extended period—a few months of parental leave—that happened to coincide with the release of a bunch of models, including the first wave of "reasoning" models like OpenAI's o1 or DeepSeek's R1. So when I returned to work I thought that it might be fun to be slightly more systematic than my normal informal testing, and compare a bunch of models all at once to see if any patterns or lessons emerged.
My results, along with some thoughts, are below. I should note that this isn't at all like a rigorous benchmarking, which (by my lights anyway) would require a broader and deeper set of questions, ideally run multiple times through these models in a variety of ways. I think that kind of benchmarking is important, and underdone in the legal realm. But I also think that more informal, qualitative writeups are undersupplied, too, when it comes to the law, especially when compared to other fields. When a new model comes out, it is easy to find many examples of people testing it with prompts about coding or general knowledge. Law, not as much. And I think that matters. There's a lot of pressure on the topic of AI for people to resolve their perspective to a tidy verdict—a thumbs up or thumbs down. But my sense is that, especially in the law, there are a lot of people who just don't have a ton of exposure to the ins and outs of everyday use of these tools—and spending some time with these tools paints a complex picture with both bright spots and blemishes.
So here's a short writeup, containing some thoughts as of March 2025. I've got my main results in a table below, along with a description of my questions and some thinking out loud about all of this.
Here's a table with my results:
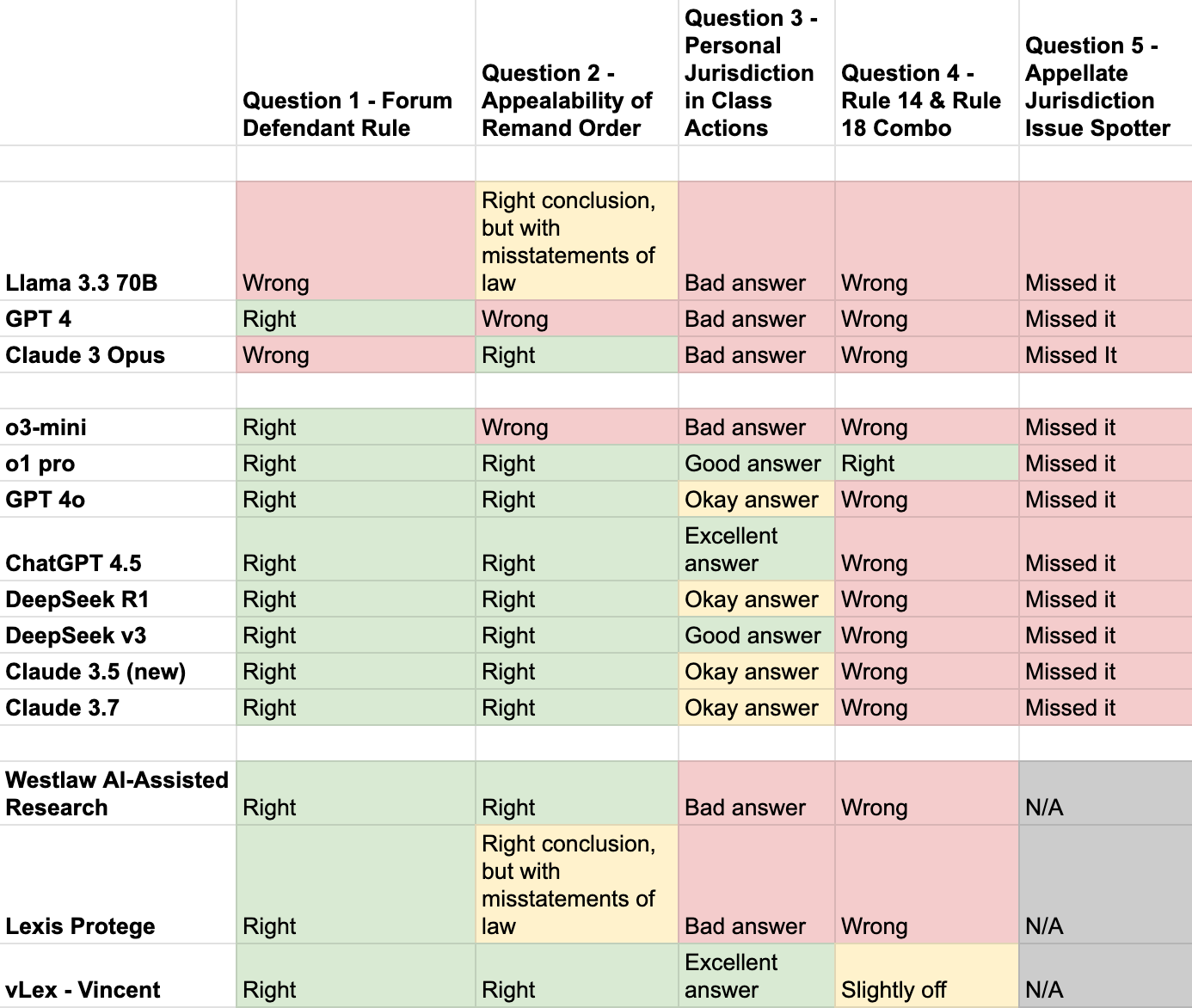
Now to explain what all is going on in this table:
The models
There are a few groupings here to delineate. First, the first set of models is, roughly speaking, the set that I was expecting to do less well. This is a combination of the models being older or "less capable" in some sense. GPT 4 was released in spring of 2023, Claude 3 was released in spring of 2024; Llama 3.3 70B is closer to the frontier, but is designed largely as a more efficient, somewhat pared-down version of an older model. None of these three is a “reasoning” model. In contrast, the second set of models is more at the current frontier—including some reasoning models like o1 pro and R1. And finally, the last set of models are three models designed specifically for legal use: Westlaw's “AI-Assisted Research” tool, Lexis’s “Protege” tool, and vLex's “Vincent” tool. (As a disclosure, Ed Walters, the Chief Strategy Officer at vLex, teaches at Georgetown where I teach as well. I believe he may have helped the Georgetown Law Library get some free trials of Vincent for faculty at Georgetown, which I have used, but that is the full extent of his connection to this post.)
The questions
Next, the questions. I teach Civil Procedure, and used some questions that I ask students in class as well as on past final exams. These were designed to be roughly increasing in difficulty, with some important differences in kind in addition to that difference of degree.
Question One was a very basic question—it asked whether, in a particular scenario, a defendant in a lawsuit that was filed in state court could “remove” the case to federal court. The answer was a clear no because of a well-established rule called the “forum defendant rule.” Two models (Claude 3 Opus and Llama 3.3 70B) got this wrong, but every other model got it right.
Question Two was somewhat more complicated: it involved another question about removal, but this was about whether a particular type of court order was appealable. Again, the answer was no, because of a statutory limit on the appealability of this type of order. But there is an extra difficulty here, which is that the underlying order was wrongly decided (and a common step that a party in a lawsuit will take when it encounters an erroneous decision is to appeal that decision if that's possible). So there was an obvious wrong path for the LLMs to take, talking about how the order was wrongly decided and so should be appealed. Most of the language models still managed this one, although interestingly Lexis's specialized legal AI tool (along with Llama 3.3 70B) said some false things in its answer despite ultimately arriving at the right conclusion.
Question Three was the question that yielded the biggest spread in answer quality. It asked about an area of law (personal jurisdiction in class actions) where there is currently some uncertainty, with dozens of federal district courts coming out on different sides of the issue and only a few circuit courts weighing in. Notably, this uncertainty is about eight years old at this point, and has been written about in many different forums in that time—plenty of time to make its way into LLM training data.
On this question, several LLMs—including the Westlaw and Lexis AI tools—gave some sort of coherent answer but did not acknowledge the existence of any contrary authority or other reason to doubt their answer (I marked this as a “bad answer”) on the table. Some of these answers also mischaracterized the most relevant Supreme Court case (Bristol-Myers Squibb). A few more gave answers that articulated the majority rule and included vague statements consistent with the existence of uncertainty or a split of authority, but not directly stating it—these are the “okay answers” in the table. A couple tools gave good answers acknowledging the uncertainty. And two tools—ChatGPT 4.5 and Vincent—stood out as having particularly complete and thorough discussions of the issue.
Questions Four and Five were “issue spotter” questions excerpted from my final exam. This entails a kind of short story with a lot of legal issues thrown in for the test-taker to “spot” and discuss. Question Four involved an issue that was clearly delineated in the text—the reader was asked to discuss whether it was permissible to join a specific claim against a third-party defendant in a lawsuit if that claim was unrelated to the lawsuit. The difficulty here was that if the claim were standing on its own, the answer would be a clear “no” under Rule 14—but because there was already an appropriate, related claim against the third-party defendant, it was permissible to add the unrelated one as well, under Rule 18. (Yeah, it’s complicated). Every AI tool got this wrong except for o1 pro, including the specialized legal tools (Vincent did an okay job, but still got the answer slightly off). They also all tended to get it wrong in the same way, applying Rule 14 and saying the claim needed to be related, ignoring the Rule 18 nuance that was added by the presence of the preexisting claim.
Question Five was an issue of appellate jurisdiction that was more “hidden” in the issue spotter—there was no direct text asking the reader specifically about appellate jurisdiction, although there was a general call to address any jurisdictional issues. Every model missed this. And most of my students missed this one too! But, as I tell my students, the world will not always give legal issues to you in a nicely identified and labeled form, so identifying an issue that is present without being told that it is present is an important legal skill. It seems like it’s a skill that the LLMs have yet to master, at least when it comes to appellate jurisdiction. To be fair to the specialized law tools, they don't really pretend to be equipped for this, and in fact could not even ingest the full text of the issue spotter question, so I marked this as "N/A" for them.
Reflections
So what does all this suggest? Like I said above, this is not the kind of testing that you should take to the bank—this is the kind of short, informal testing that is good for creating some working impressions rather than firm conclusions. But what are those working impressions?
First, it seems like the new wave of models are doing better with legal questions than the old ones. This is true of both the “reasoning” models and just the most advanced versions of the “traditional” models (or whatever we are calling the non-reasoning models, like ChatGPT 4.5 or Claude 3.5 new). They got more answers right. And, more subjectively, they did a better job at explaining and articulating their answers. OpenAI's o1 pro, a reasoning model, was also the only model to get my Question Four correct—including the specialized legal AI tools, although Vincent came pretty close.
Second, I still would not really trust any AI tool to answer a legal question in any setting with any significant consequences attached. Look at all the red and yellow on that table. The closest tool I could imagine using for the task of "answering legal questions" is Vincent, in part because of the higher quality of its answers and in part because its citation and interface make it easy to check those answers—which as these results indicate, you really have to do. And even then, I would still do some research on my own, as false negatives seem like a problem everywhere, too. These tools are incredible in many ways, but they aren't (yet?) at the “ask it a legal question and you can simply rely on the answer” stage. That isn't to say they are useless—there are many, many things you can productively use an LLM for in legal practice other than relying on it to generate correct answers to legal research questions. But they are definitely not oracles for legal questions.
Third, it seems possible that these questions delineate a few kinds of common failings of LLMs when it comes to legal questions (although count this all as impressionistic and highly speculative):
As Question Five suggests, one of these failings may just be issue spotting where the relevant input does not give strong hints or cues to look for a particular type of issue—like where an appellate jurisdiction issue is lurking in the midst of a few other legal questions, but no part of the prompt suggests that fact explicitly.
Question Three also might suggest that LLMs have difficulty dredging up contrary lines of precedent where there is a split of authority but one dominant viewpoint, even if those contrary lines are still real and active in some jurisdictions. But that's a pretty big conclusion to draw from this one example, so take this hypothesis as even more tentative than the other ones I'm suggesting here.
Question Four raises an interesting possibility to me, which is that LLMs might have difficulty teasing apart exceptions from rules where the inputs that trigger the exception look very similar to the inputs that trigger the rules. Seeing model after model repeat the exact same flawed reasoning about Rule 14 certainly made it seem like something in the models was pushing them in the direction of wanting to focus on applying the relatedness test that that Rule demands. Maybe that's just much more prevalent in their training data, or "looks like" something that is more common. That could just be specific to this tiny corner of the universe of legal text, but I could also imagine it reflecting a more difficult issue: that often, the application of a rule will be common, and the application of its exception will be rare—and so, for AI models built on predictive engines, teasing apart the exception from the rule could be difficult. Again, that's just speculation, but Question Four didn't seem all that much more difficult to me than Question Two—and yet the distribution of results was the complete opposite.
Alright, that’s enough speculation for now. I also hope to write at some point about some of the more systematic empirical work that has been done to test LLMs on legal questions. And I may come back and update this down the road when new models come out.